[CV] OCR (Optical Character Recognition)
What is OCR (Optical Character Recognition)?
OCR is a tool to allow computers to recognize the text from physical documents to be interpreted as data. When we read text on a document, whether it’s on physical paper or on the computer screen, we instantly know what letter or other symbols it is. However, for computers, it’s a little more complicated.Certain programs use OCR to allow you to edit the text from the scanned document like you would in a word processor. You can highlight text, copy it to other documents or rewrite whole sections. Another use for OCR is to make full-text searching a possibility. Some OCR programs will add the text recognized from a scanned document as metadata to the file, allowing certain programs to search for the document using any text contained within the document.
Applications
Widely used as a form of information entry from printed paper data records – whether passport documents, invoices, bank statements, computerized receipts, business cards, mail, printouts of static-data, or any suitable documentation – it is a common method of digitizing printed texts so that they can be electronically edited, searched, stored more compactly, displayed on-line, and used in machine processes such as cognitive computing, machine translation, (extracted) text-to-speech, key data and text mining. OCR is a field of research in pattern recognition, artificial intelligence and computer vision.
Open Source Libraries
- Tesseract
- Python pyocr
- OCR of Hand-written Data using kNN
- Ocropy
- East Text Detector:
- https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector
- https://arxiv.org/pdf/1704.03155.pdf
Factors relating to OCR Tasks
- Text density: on a printed/written page, text is dense. However, given an image of a street with a single street sign, text is sparse.
- Structure of text: text on a page is structured, mostly in strict rows, while text in the wild may be sprinkled everywhere, in different rotations.
- Fonts: printed fonts are easier, since they are more structured then the noisy hand-written characters.
- Character type: text may come in different language which may be very different from each other. Additionally, structure of text may be different from numbers, such as house numbers etc.
- Artifacts: clearly, outdoor pictures are much noisier than the comfortable scanner.
- Location: some tasks include cropped/centered text, while in others, text may be located in random locations in the image.
Tasks
Street House Numbers - SVHN dataset.
House numbers extracted from Google StreetView. The digits come in various shapes and writing styles, however, each house number is located in the middle of the image, thus detection is not required. The images are not of a very high resolution, and their arrangement may be a bit peculiar.
License plates
Not very hard and useful in practice. This task, as most OCR tasks, requires to detect the license plate, and then recognizing it’s characters. Since the plate’s shape is relatively constant, some approach use simple reshaping method before actually recognizing the digits.
CAPTCHASince the internet is full of robots, a common practice to tell them apart from real humans, are vision tasks, specifically text reading, aka CAPTCHA. Many of these texts are random and distorted, which should make it harder for computer to read. I’m not sure whoever developed the CAPTCHA predicted the advances in computer vision, however most of today text CAPTCHAs are not very hard to solve, especially if we don’t try to solve all of them at once.
PDF OCR
The most common scenario for OCR is the printed/pdf OCR. The structured nature of printed documents make it much easier to parse them. Most OCR tools (e.g Tesseract) are mostly intended to address this task, and achieve good result. Therefore, I will not elaborate too much on this task in this post.
OCR in the wildThis is the most challenging OCR task, as it introduces all general computer vision challenges such as noise, lighting, and artifacts into OCR. Some relevant data-sets for this task is the coco-text, and the SVT data set which once again, uses street view images to extract text from.
Synth textSynthText is not a data-set, and perhaps not even a task, but a nice idea to improve training efficiency is artificial data generation. Throwing random characters or words on an image will seem much more natural than any other object, because of the flat nature of text.
We have seen earlier some data generation for easier tasks like CAPTCHA and license plate. Generating text in the wild is a little bit more complex. The task includes considering depth information of an image. Fortunately, SynthText is a nice work that takes in images with the aforementioned annotations, and intelligently sprinkles words (from newsgroup data-set).
Mnist
Although not really an OCR task, it is impossible to write about OCR and not include the Mnist example. The most well known computer vision challenge is not really an considered and OCR task, since it contains one character (digit) at a time, and only 10 digits. However, it may hint why OCR is considered easy. Additionally, in some approaches every letter will be detected separately, and then Mnist like (classification) models become relevant.
General Steps
Optical character recognition works in roughly five steps:First, you need to have input: an image which you want to extract text from. This image can be a picture or a scan. This matters, because scanners mostly make straight pictures of the subject (the piece of text in the image is more likely to be aligned with the edges of the image), while photos can be more difficult to use.
Second, you can preprocess the image. This means that the brightness and contrast can be adjusted, the text within the image aligned with the borders of the image, any perspective that exists within a photo can be corrected, etcetera. These preprocessing steps help to improve the accuracy of the recognition, meaning you'll get less errors in the resulting text.
As the third step, the image is seperated into zones. For example, you're trying to extract text from a newspaper. It might contain images, text, and whitespace. In this step, the software determines where on the page the text is, so it knows where to start with the next step.
Fourth, the characters are classified. The text zones are divided into lines, and then into characters. The characters are then matched using various algorithms. This results in the text that we wanted to retrieve from the image.
As a final step, post-processing can be done. The found text might contain some errors or mistakes from the previous step. It might contain words that don't make sense, or misspelled words. Using a dictionary, the software can fix those words.
Optical character recognition thus works in roughly five steps: getting the input, preprocessing, extracting regions, classifying characters, and post-processing.
Since this question is tagged with Evernote, you might be interested in reading more about [Evernote's specific implementation](https://blog.evernote.com/tech/2...)
Strategies
Text recognition is mostly a two-step task. First, you would like to detect the text(s) appearances in the image, may it be dense (as in printed document) or sparse (As text in the wild). Then, you perform the text transcription to figure out what the content of the text is.Three main approaches for the first step (text detection) are:
1. Classic computer vision techniques
Require many manual tweaking - not very useful.
2. Specialized deep learning approaches
2a. EAST (Efficient accurate scene text detector)
This is a simple yet powerful approach for text detection. Using a specialized network.
https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector
https://arxiv.org/pdf/1704.03155.pdf
2b. CRNN
Convolutional-recurrent neural network, is an article from 2015, which suggest a hybrid (or tribrid?) end to end architecture, that is intended to capture words, in a three step approach.
The idea goes as follows: the first level is a standard fully convolutional network. The last layer of the net is defined as feature layer, and divided into “feature columns”. See in the image below how every such feature column is intended to represent a certain section in the text.
https://arxiv.org/pdf/1704.03155.pdf
2b. CRNN
Convolutional-recurrent neural network, is an article from 2015, which suggest a hybrid (or tribrid?) end to end architecture, that is intended to capture words, in a three step approach.
The idea goes as follows: the first level is a standard fully convolutional network. The last layer of the net is defined as feature layer, and divided into “feature columns”. See in the image below how every such feature column is intended to represent a certain section in the text.
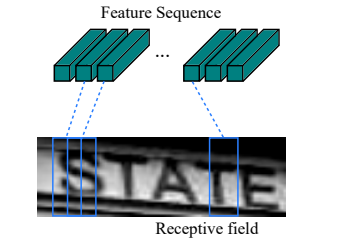
Afterwards, the feature columns are fed into a deep-bidirectional LSTM which outputs a sequence, and is intended for finding relations between the characters.
Finally, the third part is a transcription layer. Its goal is to take the messy character sequence, in which some characters are redundant and others are blank, and use probabilistic method to unify and make sense out of it.
This method is called CTC loss, and can be read about here. This layer can be used with/without predefined lexicon, which may facilitate predictions of words.
This paper reaches high (>95%) rates of accuracy with fixed text lexicon, and varying rates of success without it.
2c. STN-net/SEE
SEE — Semi-Supervised End-to-End Scene Text Recognition, is a work by Christian Bartzi. He and his colleagues apply a truly end to end strategy to detect and recognize text. They use very weak supervision (which they refer to as semi-supervision, in a different meaning than usual ). as they train the network with only text annotation (without bounding boxes). This allows them use more data, but makes their training procedure quite challenging, and they discuss different tricks to make it work, e.g not training on images with more than two lines of text (at least at the first stages of training).
3. Standard deep learning approach
SSD and other detection models are challenged when it comes to dense, similar classes, as reviewed here. I find it a bit ironic since in fact, deep learning models find it much more difficult to recognize digits and letters than to recognize much more challenging and elaborate objects such as dogs, cats or humans. They tend no to reach the desired accuracy, and therefore, specialized approaches thrive.
SSD and other detection models are challenged when it comes to dense, similar classes, as reviewed here. I find it a bit ironic since in fact, deep learning models find it much more difficult to recognize digits and letters than to recognize much more challenging and elaborate objects such as dogs, cats or humans. They tend no to reach the desired accuracy, and therefore, specialized approaches thrive.


Comments
Post a Comment