[CV] Introduction to Object Detection
A 2019 Guide to Object Detection
1) Introduction
Object detection is a computer vision technique whose aim is to detect objects such as cars, buildings, and human beings, just to mention a few. The objects can generally be identified from either pictures or video feeds. Object detection has been applied widely in video surveillance, self-driving cars, and object/people tracking. In this piece, we’ll look at the basics of object detection and review some of the most commonly-used algorithms and a few brand new approaches, as well.
Object detection usually involves two processes; classifying and object’s type, and then drawing a bounding box. Common object detection model architectures:
- R-CNN
- Fast R-CNN
- Faster R-CNN
- Mask R-CNN (todo)
- SSD (Single Shot MultiBox Defender)
- YOLO (You Only Look Once)
- Objects as Points (todo)
- Data Augmentation Strategies for Object Detection (todo)
2.1) Why not use standard CNN?
The major reason why you cannot proceed with this problem by building a standard convolutional network followed by a fully connected layer is that, the length of the output layer is variable — not constant, this is because the number of occurrences of the objects of interest is not fixed.
A naive approach to solve this problem would be to take different regions of interest from the image, and use a CNN to classify the presence of the object within that region. The problem with this approach is that the objects of interest might have different spatial locations within the image and different aspect ratios. Hence, you would have to select a huge number of regions and this could computationally blow up. Therefore, algorithms like R-CNN, YOLO etc have been developed to find these occurrences and find them fast.
2.2) R-CNN Model
To bypass the problem of selecting a huge number of regions, Ross Girshick et al. proposed a method where we use selective search to extract just 2000 regions from the image and he called them region proposals. Therefore, now, instead of trying to classify a huge number of regions, you can just work with 2000 regions.
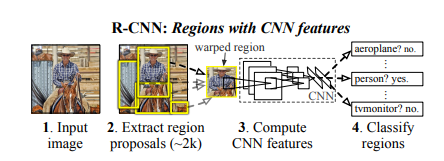
These 2000 candidate region proposals are warped into a square and fed into a convolutional neural network that produces a 4096-dimensional feature vector as output. The CNN acts as a feature extractor and the output dense layer consists of the features extracted from the image and the extracted features are fed into an SVM to classify the presence of the object within that candidate region proposal.
In addition to predicting the presence of an object within the region proposals, the algorithm also predicts four values which are offset values to increase the precision of the bounding box. For example, given a region proposal, the algorithm would have predicted the presence of a person but the face of that person within that region proposal could’ve been cut in half. Therefore, the offset values help in adjusting the bounding box of the region proposal.
Problems with R-CNN
Problems with R-CNN
- It still takes a huge amount of time to train the network as you would have to classify 2000 region proposals per image.
- It cannot be implemented real time as it takes around 47 seconds for each test image.
- The selective search algorithm is a fixed algorithm. Therefore, no learning is happening at that stage. This could lead to the generation of bad candidate region proposals.
- Training is a multi-stage pipeline. Tuning a convolutional neural network on object proposals, fitting SVMs to the ConvNet features, and finally learning bounding box regressors.
2.3) Fast R-CNN
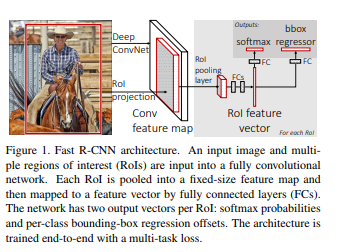
The same author of the previous paper(R-CNN) solved some of the drawbacks of R-CNN to build a faster object detection algorithm and it was called Fast R-CNN. The approach is similar to the R-CNN algorithm. But, instead of feeding the region proposals to the CNN, we feed the input image to the CNN to generate a convolutional feature map (which is same as ‘feature map of the image’). The process of generating a convolutional feature map uses selective search.
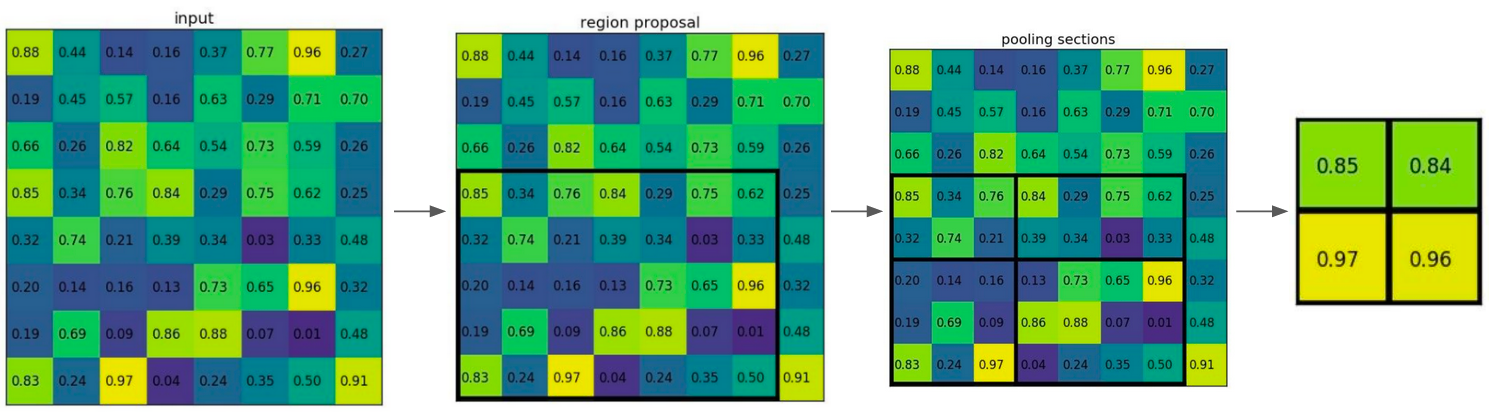
For each region proposal, extract the corresponding part from the feature map. We will call this the region proposal feature map. We take the region proposal feature map from the feature map and resize it to a fixed size with the help of a pooling layer. This pooling layer is called the Region of interest (RoI) pooling layer. Then we flatten this fixed sized region proposal feature map. This is now a feature vector, that always has the same size.
These then branch into 2 output layers. The first is the softmax classification layer, where we decide/estimate which object class we found. The second it the Bounding Box Regressor, where we output the bounding box coordinates for each object class.
The reason “Fast R-CNN” is faster than R-CNN is because you don’t have to feed 2000 region proposals to the convolutional neural network every time. Instead, the convolution operation is done only once per image and a feature map is generated from it.


From the above graphs, you can infer that Fast R-CNN is significantly faster in training and testing sessions over R-CNN. When you look at the performance of Fast R-CNN during testing time, including region proposals slows down the algorithm significantly when compared to not using region proposals. Therefore, region proposals become bottlenecks in Fast R-CNN algorithm affecting its performance.
2.4) Faster R-CNN

Both of the above algorithms(R-CNN & Fast R-CNN) uses selective search to find out the region proposals. Selective search is a slow and time-consuming process affecting the performance of the network. Therefore, Shaoqing Ren et al. came up with an object detection algorithm that eliminates the selective search algorithm and lets the network learn the region proposals.
Similar to Fast R-CNN, the image is provided as an input to a convolutional network, which provides a convolutional feature map. Instead of using selective search algorithm on the feature map to identify the region proposals, a separate network is used to predict the region proposals. The predicted region proposals are then reshaped using a RoI pooling layer which is then used to classify the image within the proposed region and predict the offset values for the bounding boxes.

From the above graph, you can see that Faster R-CNN is much faster than it’s predecessors. Therefore, it can even be used for real-time object detection.
2.5) Single Shot Detectors (SSD)
By using SSD, we only need to take one single shot to detect multiple objects within the image, while regional proposal network (RPN) based approaches such as R-CNN series that need two shots, one for generating region proposals, one for detecting the object of each proposal. Thus, SSD is much faster compared with two-shot RPN-based approaches.
After going through a certain of convolutions for feature extraction, we obtain a feature layer of size m×n (number of locations) with p channels, such as 8×8 or 4×4 above. And a 3×3 conv is applied on this m×n×p feature layer.
For each location, we got k bounding boxes. These k bounding boxes have different sizes and aspect ratios. The concept is, maybe a vertical rectangle is more fit for human, and a horizontal rectangle is more fit for car.
For each of the bounding box, we will compute c class scores and 4 offsets relative to the original default bounding box shape.
Thus, we got (c+4)kmn outputs.

2.6) YOLO — You Only Look Once
All of the previous object detection algorithms use regions to localize the object within the image. The network does not look at the complete image. Instead, parts of the image which have high probabilities of containing the object. YOLO or You Only Look Once is an object detection algorithm much different from the region based algorithms seen above. In YOLO a single convolutional network predicts the bounding boxes and the class probabilities for these boxes.

How YOLO works is that we split the image into an SxS grid, within each of the grid we take m bounding boxes. For each of the bounding box, the network outputs a class probability and offset values for the bounding box. The bounding boxes having the class probability above a threshold value is selected and used to locate the object within the image.
YOLO is orders of magnitude faster(45 frames per second) than other object detection algorithms. The limitation of YOLO algorithm is that it struggles with small objects within the image, for example it might have difficulties in detecting a flock of birds. This is due to the spatial constraints of the algorithm.


Comments
Post a Comment